巴卡漫画新闻
College News

近日,国际计算机视觉会议(International Conference on Computer Vision,ICCV)公布了2025年的论文录用结果。巴卡漫画 先进智能与机器视觉研究所 (AIMC-Lab) 关于草图动画生成、跨模态视频检索、视频自动配乐等三项研究成果被ICCV2025录用。 ICCV与CVPR、ECCV并称计算机视觉三大顶会(CCF-A)。此次ICCV收到有效投稿 11,239 篇,最终录用2,698 篇,录用率为24%。会议将于 2025 年 10 月 19 日至 23 日在美国夏威夷举行。
论文一简介
题目:Multi-Object Sketch Animation by Scene Decomposition and Motion Planning
作者:刘靖宇,辛梓杰,傅毓晗,赵瑞祥,兰邦翔,李锡荣
通讯作者:李锡荣
论文概述:
草图动画生成(Sketch Animation)是一个将静态的草图图片转化为动态的草图动画的过程,在GIF设计、卡通制作和日常娱乐中有着广泛应用。现有草图动画生成方法在单物体草图动画生成上取得不少优秀成果,但是在场景级的多物体草图上表现不佳。本文专门针对这一痛点展开研究。
通过分析现有方法在多物体草图动画生成的表现,我们发现了现有方法在两个方面存在严重不足:物体级别的运动建模(object-aware motion modeling)和复杂运动的学习优化(complex motion optimization)。为此,我们提出了多物体草图动画生成方法MoSketch,通过四个模块来高效解决以上两大挑战:基于大模型的场景分解(LLM-based scene decomposition),基于大模型的运动规划(LLM-based motion planning),运动修正网络(motion refinement network)以及分而治之的学习优化(compositional SDS)。我们借助大模型的知识对多物体草图的各个物体进行初步运动规划,然后通过运动修正网络修正物体级别的运动以及建模物体内部的运动,最后采用分而治之的思想,将复杂的多物体运动进行拆解并逐一优化。我们的方法采用迭代优化的学习策略,不需要任何训练数据。
我们的方法MoSketch在自建和公共的多物体草图数据集上取得了不错的动画生成效果,在单物体草图上也有一定优势。大量的消融实验也表明我们提出的四个模块的有效性。MoSketch在多物体草图动画生成领域迈出了开创性的一步,为未来研究和应用开辟了新途径。

论文二简介
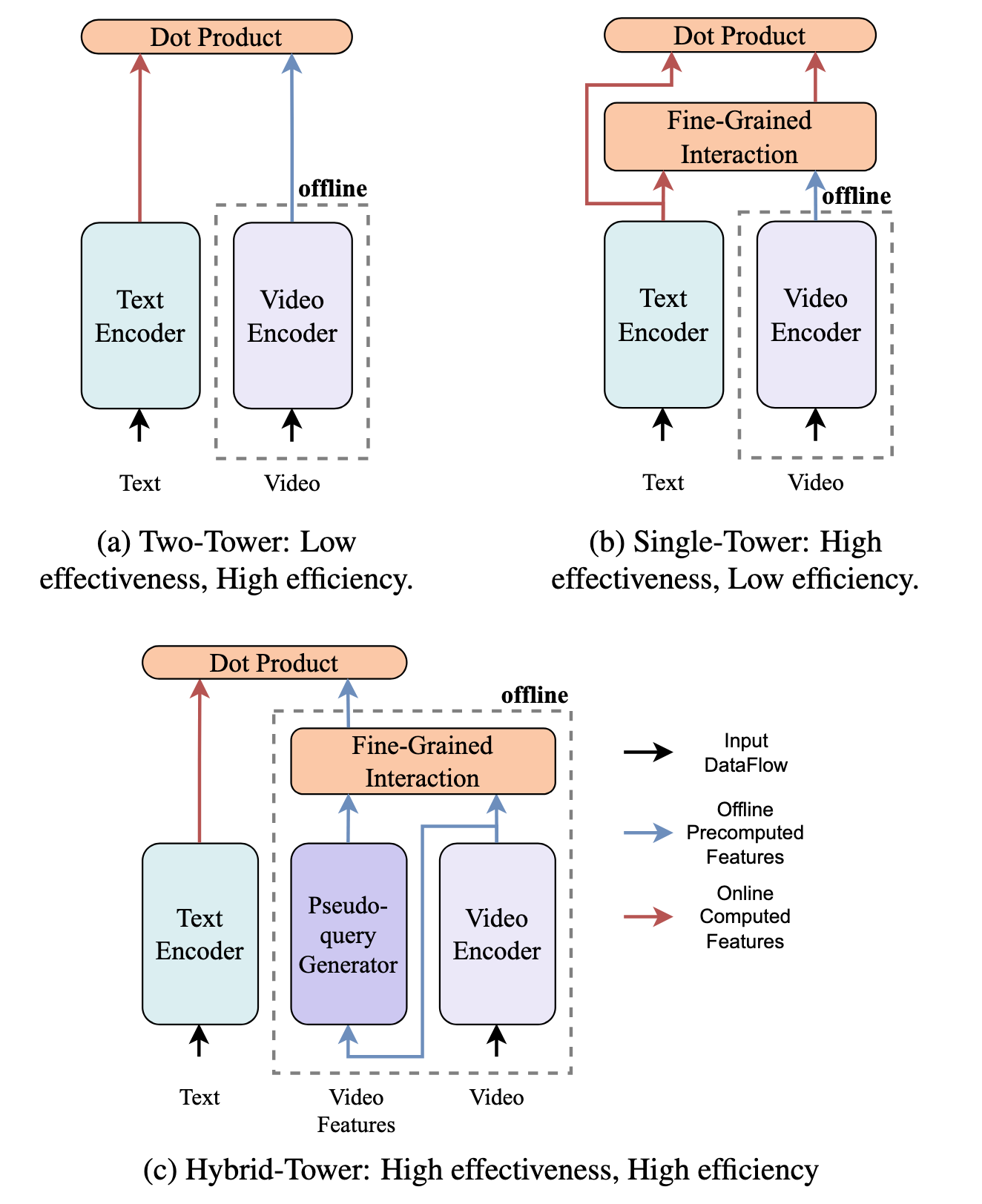
题目:Hybrid-Tower: Fine-grained Pseudo-query Interaction and Generation for Text-to-Video Retrieval
作者:兰邦翔,谢若冰,赵瑞祥,孙兴武,康战辉,杨刚,李锡荣
通讯作者:杨刚
论文概述:
随着短视频内容的爆炸式增长,如何实现高效、准确的视频内容理解与检索,成为多模态研究中的核心问题之一。其中,文本-视频检索(Text-to-Video Retrieval, T2VR)任务尤为关键,其目标是通过一段自然语言描述,在海量未标注视频中检索出语义一致的目标片段。现有的视频检索方法往往难以兼顾效率与精度,本文正是针对这一痛点展开研究。
当前主流的T2VR方法可分为“双塔架构”(Two-Tower)与“单塔架构”(Single-Tower)两类。前者通过独立编码文本和视频,并使用简单的点积计算相似度,具备较高的检索效率;后者则引入精细的交互模块以实现更强的语义对齐,通常能获得更优的检索准确性。然而,由于单塔模型中的交互过程依赖实时文本查询,导致检索效率显著下降,难以满足实际应用中对时效性的要求。
为兼顾精度与效率这一挑战,本文提出了一种全新的混合塔式检索框架(Hybrid-Tower),首次尝试融合单塔结构的细粒度语义交互能力与双塔结构的高效计算优势。我们的方法引入了新颖的伪查询生成器(Pseudo-query Generator)和伪交互融合器(Pseudo-interaction Fusioner),能够在真实查询到来之前为每个视频生成具有语义代表性的伪查询,从而提前完成精细的语义融合。该设计使得我们既能获得类单塔方法的精度,又无需在推理阶段引入额外计算开销,从而保持类双塔方法的速度优势。
在五个主流T2VR评测集上开展的大量实验验证了我们方法的有效性。本文为T2VR任务中精度与效率兼得提供了一种新范式,也为多模态检索领域的后续研究与应用提供了新的思路。
论文三简介
题目:Music Grounding by Short Video
作者:辛梓杰,王敏全,刘靖宇,马也,陈权,江鹏,李锡荣
通讯作者:李锡荣
论文概述:
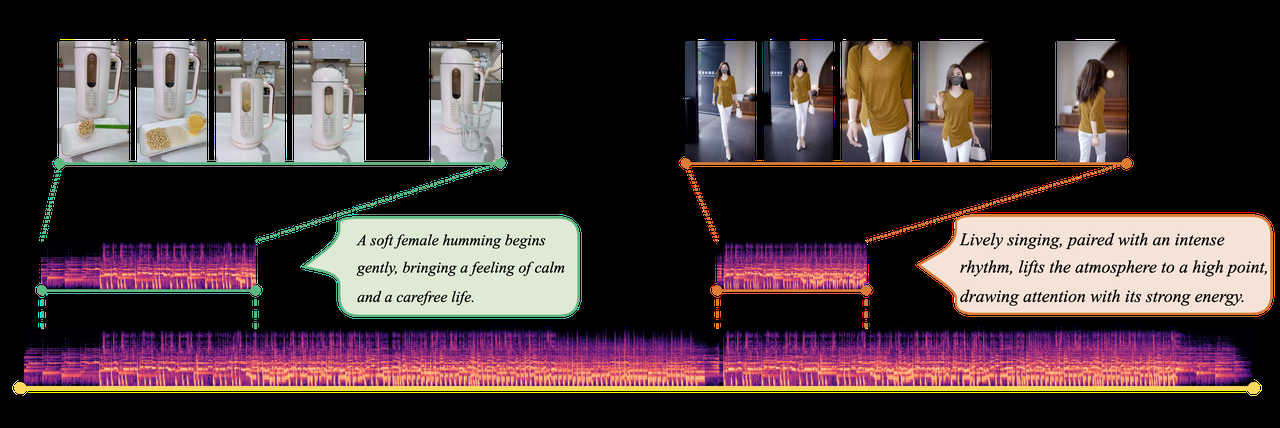
短视频配乐作为提升视频传播效果的重要环节,日益受到学术界和工业界的关注。现有的视频到音乐检索(Video-to-music Retrieval, V2MR)研究主要关注如何从特定的乐曲库中找到最合适的音乐。但实际应用中,乐曲的时长通常远大于短视频的时长。为了同时适配视频内容与时长,用户还需要再手动对返回的乐曲进行定位和裁剪,费时费力。
为了解决上述问题,本文首次提出了一种全新的任务:短视频音乐定位(Music Grounding by Short Video, MGSV)。具体而言,给定一个待配乐的短视频,MGSV旨在从乐曲库中检索到与之最为匹配的乐曲,并通过时间定位,自动剪辑与视频时长一致的音乐片段。针对这一新任务,我们构建并发布了一个大规模基准数据集MGSV-EC,包含来自电商短视频广告平台的5.3万部短视频和来自4千多首完整音乐的3.5万个音乐片段。同时,我们提出了一个统一的视频-音乐匹配与音乐片段定位基准方法MaDe。MaDe采用端到端的深度网络架构,能够同时完成视频-音乐匹配(Video-Music Matching)以及音乐片段检测(Music Moment Detection)任务。在MGSV-EC上的大量实验结果表明,该任务极具挑战性,而MaDe方法表现出明显优于现有方法的优势,可作为MGSV任务的强力基线。
本文不仅提出了一项具有实际意义的任务MGSV及相应数据集MGSV-EC,还明确了该领域未来研究的重要方向。相关数据及代码均已开源。
主要作者简介

刘靖宇,巴卡漫画 2023级博士生,专业为大数据科学与工程,主要研究方向为视觉内容生成与编辑,入选“巴卡漫画 拔尖创新人才培育资助计划”。

兰邦翔,巴卡漫画 2023级博士生,专业为大数据科学与工程,主要研究方向为多模态学习与跨模态检索。

辛梓杰,巴卡漫画 2024级博士生,专业为大数据科学与工程,主要研究方向为多模态大模型。
通讯作者简介

李锡荣,巴卡漫画 教授、博导,主要研究方向为多模态人工智能、多媒体内容理解与检索、计算机视觉、AI辅助诊断等。在相关领域主要学术刊物发表论文百余篇,谷歌学术引用8000多次,入选爱思唯尔2023、2024“中国高被引学者”榜单。研究成果多次获得国内外重要学术奖项,包括ACM CIVR 2010最佳论文奖(一作)、IEEE TMM 2012年度期刊最佳论文奖(一作)、ACM SIGMM 2013年杰出博士论文奖、ACMMM 2016 Grand Challenge Award(通讯)、 2017中国多媒体大会优秀论文奖(通讯)、2022年CCF科技成果奖自然科学二等奖(第4完成人)、 2024年CCF科技成果奖科技进步三等奖(第1完成人)、2024年度中国电子学会硕士学位论文激励计划(优硕)指导教师等。曾任国际多媒体建模会议(MMM 2021)Program Co-Chair、IET Computer Vision编委。现任ACM TOMM、Multimedia Systems等编委。

杨刚,巴卡漫画 副教授。曾就职华为技术有限公司规划部工程师。研究方向为深度学习、模式识别、智慧医疗、眼科图像分析和应用研究。在相关领域高水平期刊会议发表论文六十余篇,专利多项,主持国家自然科学基金面上、北京市自然科基金面上等多个国家级、省部级项目,担任NIPS,AAAI,ACM-MM等多个顶级期刊会议的审稿人。具有多年的项目研发和项目管理经验,研发多个已部署落地的智能医疗和信息安全系统,指导学生团队获得Google大学生程序设计大赛一等奖,中国软件杯二等奖等多项竞赛奖励。
Copyright © 2015 School of Information, Renmin University of China. All rights reserved.
版权所有巴卡漫画-BL漫画官方网站 京公网安备110402430004号 | 京ICP备05066828号-1